How to [insert topic here] with R: Using the OpenAI API
Intro
The previous blog post came out over a year ago! I’m sorry I haven’t written here more often, but that’s about to change. While I haven’t been as active on this site, I’ve been more active on LinkedIn and GitHub. That has now sparked the need to write in a longer format again.
Anyway, let’s get on with it! I promised in the last post to write about APIs next, didn’t I? And that’s what I’m going to do here. It’s a different API than what I had in mind back then, but this one’s pretty exciting too!
I’ve recently gotten more into AI-generated art. I’m no expert, of course, but I’ve tried the free version of DALL-E 2, created by OpenAI. I had used it online, on my phone, but when I saw “DALL-E API Now Available in Public Beta” I knew I had to try it.
So, what are we doing here? The object here is to learn
- how to create an API request
- what to do with the content returned by this particular API request
- how to download and save many files using a for loop
- how to create a text file to save all the metadata from that API request
And the most important question is, why are we doing this? I can only speak for myself, but I find AI-generated art fascinating. And to be able to tap into that source of creativity like this is my driver here.
I’ll show you one example before we start. DALL-E 2 created this next image using the following text prompt as input:
“Living on the edge”

fig. 1 - An example image created by DALL-E 2
Now, I’m not going to go into the art of coming up with a good prompt in any more detail, but there are a lot of examples online and here’s one of them.
1. Let’s get ready
The original documentation is written for only Python, Node.js, and cURL. Now, that doesn’t have to be a problem. You have to be a little creative, that’s all. In fact, the cURL one contains all the necessary information.
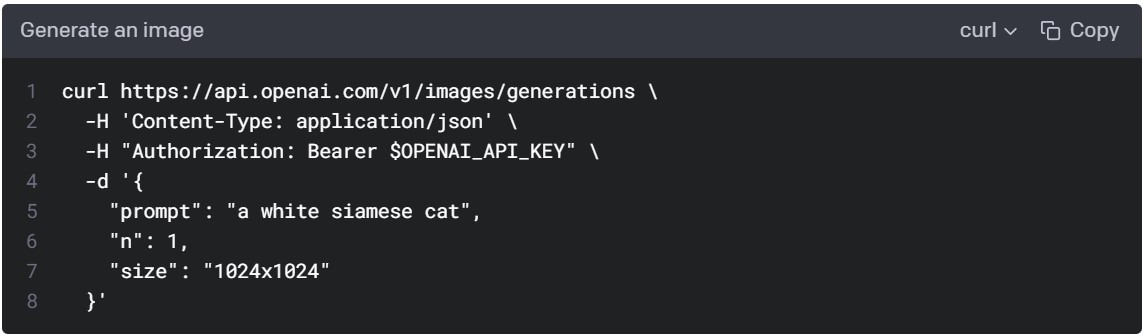
fig. 2 - cURL code for the image creation endpoint
Let’s first go through the cURL code, line by line:
- Here we have our URL: https://api.openai.com/v1/images/generations.
- Content type is json. -H indicates it’s for the header. But there’s actually an encode parameter in {httr}’s POST() function. We will insert this information there instead.
- Authorization is something we will need to put into a header. Also, there’s that $OPENAI_API_KEY part. We’ll get back to it.
- -d is indicating that the following is the body of the request:
- Prompt is the text prompt we will need to change to get the image we want
- N is the number of images that DALL-E 2 will produce with one API call
- Size is the pixel size of the image. We’ll get back to it in more detail, but it’s good to realize already that it will affect the price.
About pricing
It’s also good to start talking about money already. OpenAIs API isn’t free to use. You can see the pricing below but should check the most recent prices here.
| Image models | |
| on 2022-11-20 | |
| Resolution | Price |
|---|---|
| 1024×1024 | $0.020 / image |
| 512×512 | $0.018 / image |
| 256×256 | $0.016 / image |
There are also language models that are available (with a different pricing structure). But that is a topic for another blog post another time.
About the different cURL R packages
One last thing before we start. Even if the cURL code inspired us, we don’t have to use the cURL packages for R to use the API. And there are at least two of those that I know of: {RCurl} and {curl}. But since {httr} by Hadley Wickham is more intuitive to use, we’ll stick to that one.
2. Signing up to get the OpenAI API key
Right, I won’t go through this part of the process in any great detail. But you do need to sign up to OpenAI to be able to use the API. Sign up and give your credit card information. At the moment of writing you get “$18 in free credit that you can use during your first 3 months”, though. Use it wisely and also set up a limit you’re comfortable using per month!
After you have signed up, you need to get your OpenAI API key. You know, the one that will replace $OPENAI_API_KEY in our upcoming code. Once you have signed up and signed in, go to Personal > View API Keys and tap + Create new secret key. Copy the key and store it using something like this.
3. Loading the libraries
Let’s load the necessary packages. And as you can see, I use the terms packages and libraries interchangeably. If you don’t have one or more of them, install them first with the install.packages() function.
library(httr) # for making the API request
library(tidyverse) # for everything else
library(lubridate) # for manipulating the time stamp4. Let’s create the API request with httr
Let’s start with the arguments
Let’s go through them in the same order as they were in the documentation. We are skipping lines 4 and 8, though, as they don’t contain any important information. As you can see, it’s about recognizing the elements and writing them in the format that httr uses. When doing something like this, read the documentation, try things out and see what works (and what doesn’t).
Now, it’s important you use that API key you received. Switch it with that $OPENAI_API_KEY. Again, if you are going to use GitHub, you can store it and use it using something like this. There’s a GitHub repo I’ve made that gives you a better idea of what a finished working script looks like.
# 1. curl https://api.openai.com/v1/images/generations \
url_api <- "https://api.openai.com/v1/images/generations"
# 2. -H 'Content-Type: application/json' \
encode <- "json"
# 3. -H "Authorization: Bearer $OPENAI_API_KEY" \
authorization <- "Bearer $OPENAI_API_KEY"
# 5. "prompt": "a white siamese cat",
prompt <- "A hand drawn sketch of a UFO"
# 6. "n": 1,
n <- 1
# 7. "size": "1024x1024"
size <- "1024x1024"Let’s then create the request
First, gather the arguments as the body of the request:
body <- list(
prompt = prompt,
n = n,
size = size
)
body
## $prompt
## [1] "A hand drawn sketch of a UFO"
##
## $n
## [1] 1
##
## $size
## [1] "1024x1024"We can see that the arguments are working as they should. And now they are in the list format.
Then, the request itself:
request <- POST(
url = url_api,
add_headers(Authorization = authorization),
body = body,
encode = encode
)
request
## Response [https://api.openai.com/v1/images/generations]
## Date: 2022-11-20 11:58
## Status: 200
## Content-Type: application/json
## Size: 547 B
## {
## "created": 1668945528,
## "data": [
## {
## "url": "https://oaidalleapiprodscus.blob.core.windows.net/private/org-N...
## }
## ]
## }With that POST request, we get as many images (or URLs for those images, to be exact) as we chose earlier. This is also the part of the script that requires payment.
Finally, let’s take a look at the content
request %>%
content() %>%
glimpse()
## List of 2
## $ created: int 1668945528
## $ data :List of 1
## ..$ :List of 1
## .. ..$ url: chr "https://oaidalleapiprodscus.blob.core.windows.net/private/org-NzPmYnKPtA2OfifpIfjpaaGc/user-21McymnFfhJyBoKrAOI"| __truncated__That content() function from {httr} converts the data from the json format that it arrived in into a list with two elements: created (time stamp in seconds) and data (url(s)). Next we’ll take these individual elements as they will help us get those images. So far we only have text data!
5. Saving the individual elements
Time stamp (created)
The idea here is to use the contents we saw to take the next necessary steps. Let’s first take that created value (time of creation). Turn it into an date-time object. Then turn it into a string, so that we can use it as the basis for the filename when we get there.
created <- request %>%
content() %>%
# We take the first element 'created' of the content (in the list format)
pluck(1) %>%
# Then use {lubridate} to turn that number into a datetime object.
# We have to provide a timezone. You can see the list using this function:
# OlsonNames(). Mine happens to be "Europe/Helsinki"
as_datetime(tz = "Europe/Helsinki") %>%
ymd_hms() %>%
# Finally, let's turn the datetime object to a string and replace the
# spaces and colons with dashes, so that the filename will be cleaner
as.character() %>%
str_replace_all("\\s", "-") %>%
str_replace_all("\\:", "-")
created
## [1] "2022-11-20-13-58-48"URL(s)
Next, let’s pluck the URL(s) from the requested content and make it/them a vector. We will use that vector to next download the image(s) from the temporary address the API has saved them.
The URL(s) will expire in an hour! So you should run the script from start to finish when you’re ready. And in case you don’t know how it’s done, the easiest way to do it is to press Ctrl + Alt + R.
url_img <- request %>%
content() %>%
pluck(2) %>%
unlist() %>%
as.vector()
url_img
## [1] "https://oaidalleapiprodscus.blob.core.windows.net/private/org-NzPmYnKPtA2OfifpIfjpaaGc/user-21McymnFfhJyBoKrAOIPiG9e/img-036xIMYVvblHqY3dQLerbCeo.png?st=2022-11-20T10%3A58%3A48Z&se=2022-11-20T12%3A58%3A48Z&sp=r&sv=2021-08-06&sr=b&rscd=inline&rsct=image/png&skoid=6aaadede-4fb3-4698-a8f6-684d7786b067&sktid=a48cca56-e6da-484e-a814-9c849652bcb3&skt=2022-11-19T22%3A16%3A21Z&ske=2022-11-20T22%3A16%3A21Z&sks=b&skv=2021-08-06&sig=5X8Ogg1kVV4mviLw/J1p8R%2BoxU3uTSBI6YTEwVYNZ7o%3D"6. Downloading the images
We’ll be using a for loop to go through each of the URLs contained in the vector url_img we created.
Most of the packages we’ve been using so far have been from the {tidyverse} family of packages. But for this part we’ll be using base R functions: for loop, seq_along, paste0 and download.file. I’m quite certain there is a ‘tidy’ way to do this with {purrr} & co. but the following was the easiest/fastest way to the goal. You can always go back and update the code once it’s working.
The code has are three parts:
- for (i in seq_along(url_img)) sets up the for loop. You can read this in English: “For each URL found in the url_img vector run these following two parts”.
- Create the filename. We use the character string “dall-e”, the creation time stamp, “-”, and a running number at the end. The i means index.
For example: “dall-e-2022-11-05-22-16-12-1.png” - Download the files mentioned in the url_img. Mode = “wb”, because we’re downloading binary files. Won’t work without it. Believe me, I’ve tried.
for (i in seq_along(url_img)) {
destfile <- c(
paste0(
"images/dall-e-",
created,
"-",
i,
".png"
)
)
download.file(url_img[i], destfile, mode = "wb")
}And voilà!
fig. 3 - Another example image created by DALL-E
7. Writing the metadata in a .txt file
Gather the metadata
In case you want to know how DALL-E 2 created a particular image (using which prompt etc.) or wish to use the URL (for an hour, remember it’s gone after that), we’ll gather all the info first.
metadata <- tibble(
prompt,
n,
size,
created,
url_img,
destfile
)Create the path/filename
We’ll use one file for the image metadata (whether there are one or more images). And by using a similar naming convention, you can find everything without trouble.
file <- str_glue("images/dall-e-{created}.txt")Write the .txt file
As you can see, with tibble and str_glue we returned to the {tidyverse}. We’ll wrap things up with write_delim, a lesser-known function from the {readr} packages _write__ family of functions.
I chose a .txt file for ease of use, but with the delimiters, it’s still easy enough to read in in a tabular format.
metadata %>%
write_delim(
file = file,
delim = ";"
)The end result
And this is what it then looks like:
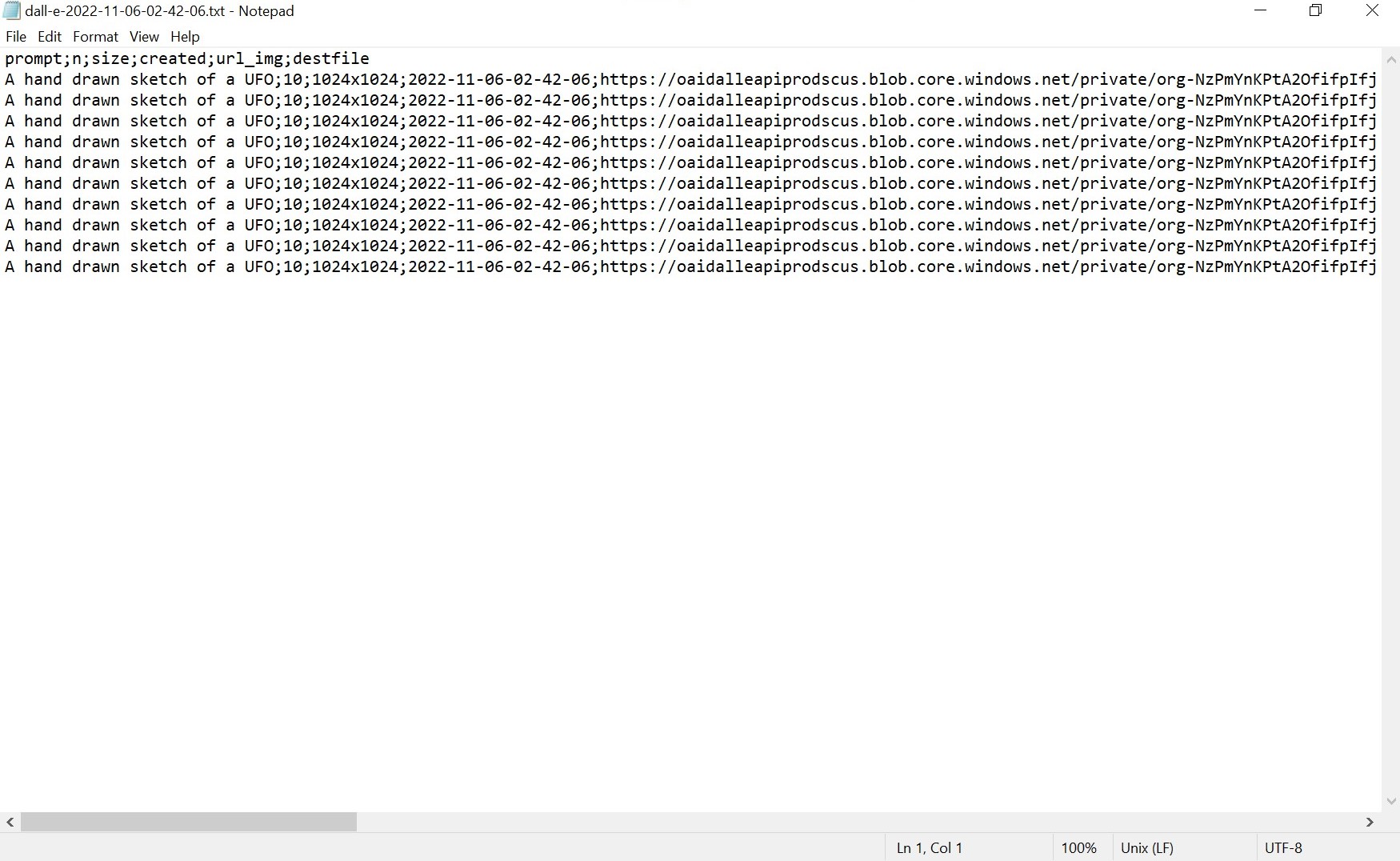
fig. 4 - An example .txt file containing the metadata
8. Conclusion
I guess it’s better not to make any grand promises since it took a year to fulfill the previous one.
But I hope you had fun with this one. And I hope you have a good time using {httr} for OpenAI API or something completely different!
I’m not promising anything, but I will probably be checking out the other APIs by OpenAI at some point. I’ll let you know if/when I do!
And just to remind you, if you wish to have a functioning R script and don’t want to build it piece by piece, you can find it on my GitHub.
Cheers!
Updated: 20 November, 2022
Created: 20 November, 2022